
For a new developer it is mostly a challenge to -
- keep track of changes in the development life cycle of a software application
- collaborate with peer developers - how to merge changes
- do some experiment, test and if it doesn't work - revert changes
- continuing of main stream development by colleagues while I experiment with some new feature
The trivial approach (I have even used in early days) is to zip the files and name it - mostly a time stamp & then continue the main development. So if something unfortunate happens, I can revert to an old version at the expense of loosing all the delta changes. This is incredibly error prone.
It was very difficult to merge the changes of peers, keep track of change history and who changed what. It was always a challenge to go to each file and undo changes while reverting a failed experiment. And if there is any miss - hours required to detect and bring things back on track.
These pain points (& many such if you can count) are addressed by Source Code Management (SCM) or also called as Version Control System (VCS).
Let's talk about evolution of Version Control Systems.
1] Local VCS - Programmers long ago developed local VCSs that had a simple database that kept all the changes to files under revision control. E.g. RCS distibuted by Mac OS X. But it doesn't address the collaboration challenge.
2] Centralized VCS - It was developed to address the need to collaborate with developers on other systems. C-VCS have a central server which keeps track of file versions and clients who have checked out. The commits made by clients hit directly to the central server. This is a lot chatty as client commits changes directly on central server.
The advantage was
- track of changes from other developers
- fine-grained control to admins for who can change what
But there are some serious downsides viz.
- The central server is single point of failure. If server goes down, the development will halt as people will not be able to checkin their changes and collaborate.
- If the HD of central server database corrupts (with no proper backup) everything is lost, except what we have in dev shadows.
It was & is being used for the projects which are on C-VCS such as CVS, Subversion & Perforce, but efforts are being made to migrate to DVCS such as git.
3] Distributed VCS - E.g. Git, Mercurial, Bazaar, Darcas
In D-VCS, client just doesn't checkout files but the fully mirror the repository. The client can now perform all the operations on the local clone of central repo. You can also collaborate with different repositories of the project. Such workflows can't be achieved in a centralized setup.
Git - A Short History
From 1991-2002 the development of Linux Kernal and changes to software were passed around as archived files. In 2002 Linux community started using a proprietary D-VCS BitKeeper.
In 2005, the relationships between developer community of Linux kernel and commercial company that owns BitKeeper broke down. This prompted Linus Torvald to build their own D-VCS better than BitKeepr based on lessons learned. They goals for new D-VCS were -
- Speed
- Simple Design
- Strong support for non-linear development
- Fully distrubuted
- Ability to handle large projects (like Linux Kernel)
And the answer to all is Git which is developed in 2005 and evolved over a period of time.
Git - Versus other VCS
Snapshots, Not Differences
Other VCS maintains data as set of files and history of changes made to each file over time. When you commit, git takes a picture of how all the files look and stores reference to the snapshot. If files haven't changed then from the snapshot there will be a link to previous identical file. So for git it is more like stream of snapshots.
Nearly Every operation is local
Most operations in git requires local files and resources to operate & no information is required from other computer on the network. -- means No Network Latency Overhead ==> SPEED. You can view your history locally.
Integrity
Everything in git is check-summed using SHA-1 hash before it is stored. It is a 40 character hexadecimal string. The first 10 characters of hash value are sufficient to identify a checkin (snapshot) uniquely.
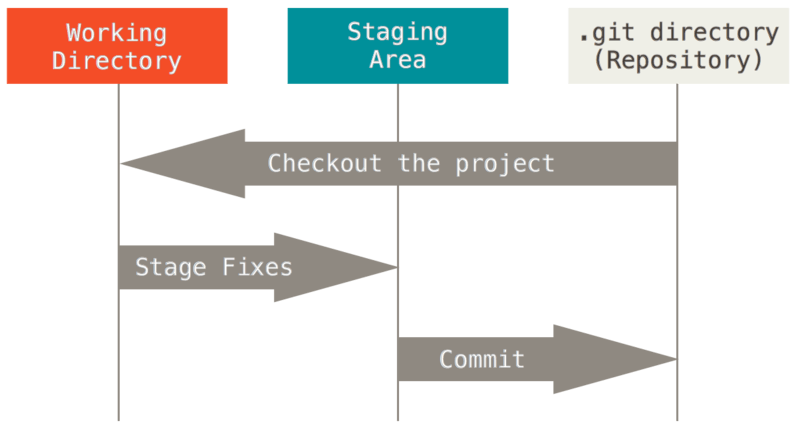
The Three States
[IMP] A git repository has three states. Each file in the repo resides in one of these states.
Modified State (Working Directory) - A git file untracked or modified will be in this state. To remove all the files which are in working directory $git clean -f
Stage (Staging Area) - A file added using $git add becomes staged. The staging area holds the files which will be committed together when next commit is made. To unstage a file remove a file from staging area and to put it back in working directory $ git rm --cached <file_name>
Commit (Repository) - $git commit adds staged file into git repository creating a snapshot.
Click here to setup and perform command line interaction with a git repository.
No comments:
Post a Comment
Your comments are very much valuable for us. Thanks for giving your precious time.